주문형 반도체 Floorplan 자동화 (1)

주문형 반도체 Floorplan 자동화 (1)
MakinaRocks의 COP(Combinatorial Optimization Problem) 팀에서는 주문형 반도체(Application Specific Integrated Circuit, ASIC)에서의 소자 배치를 자동화하는 Floorplan Automation 프로젝트를 진행하고 있습니다. 저희는 총 2부에 걸쳐 진행한 Floorplan Automation 프로젝트에 대해서 소개하고자 합니다. 이번 포스팅에서는 산업에서 Floorplan Automation이 산업에서 어떠한 의미를 갖는지, COP 팀이 현재 해결하고 있는 문제와 그 결과에 대해 무엇인지 요약하겠습니다. 그리고 다음 2부에서는 COP 팀이 문제를 어떻게 해결했는지 자세하게 설명하겠습니다.
Related to
1. ASIC Design
이번 장에서는 Floorplan이 ASIC 설계의 어느 과정에 해당하고, Floorplan 자동화가 어떤 의의를 갖는지 설명드리겠습니다.
1.1 ASIC이란
먼저 ASIC에 대해서 알아보겠습니다. ASIC이란 Application Specific Integrated Circuit의 약자로 가전, 휴대폰, 자동차 등 특정한 제품을 위해 주문 제작한 반도체입니다. ASIC은 요구되는 주문 사항을 만족시키기 위해 낮은 소비전력 (Power), 빠른 속도 (Performance), 높은 집적도 (Area)를 목표로 합니다.
1.2 ASIC Design Flow
ASIC 설계는 System-Level Design, Logic Design, Physical Design 세 단계로 진행됩니다.
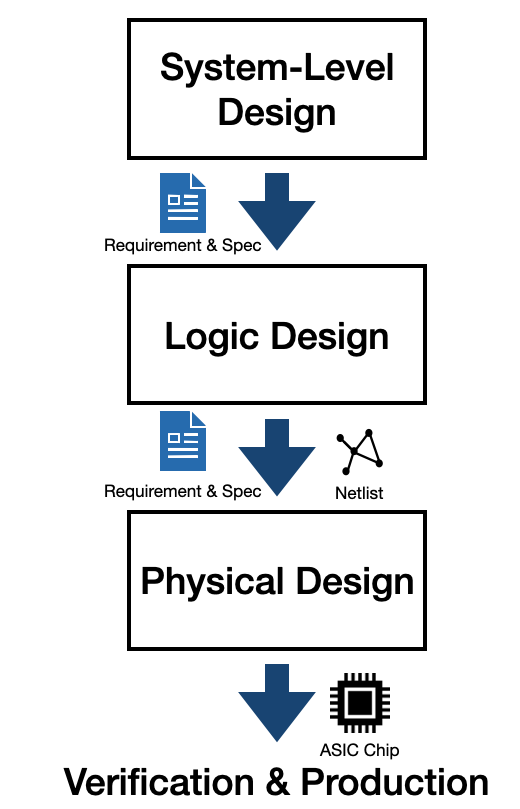
[그림1] - ASIC Design Flow
System-level Design 단계에서는 ASIC이 제공해야 할 기능, Power, Timing 그리고 Area와 같은 ASIC 스펙 등을 정의합니다.
이후 Logic Design 단계에서는 정의한 스펙에 맞는 Netlist를 생성합니다. Netlist는 Net의 집합입니다. Net은 각 소자가 어떤 소자로부터 전기신호를 받고 어떤 소자로 전기신호를 보내는지 나타냅니다.
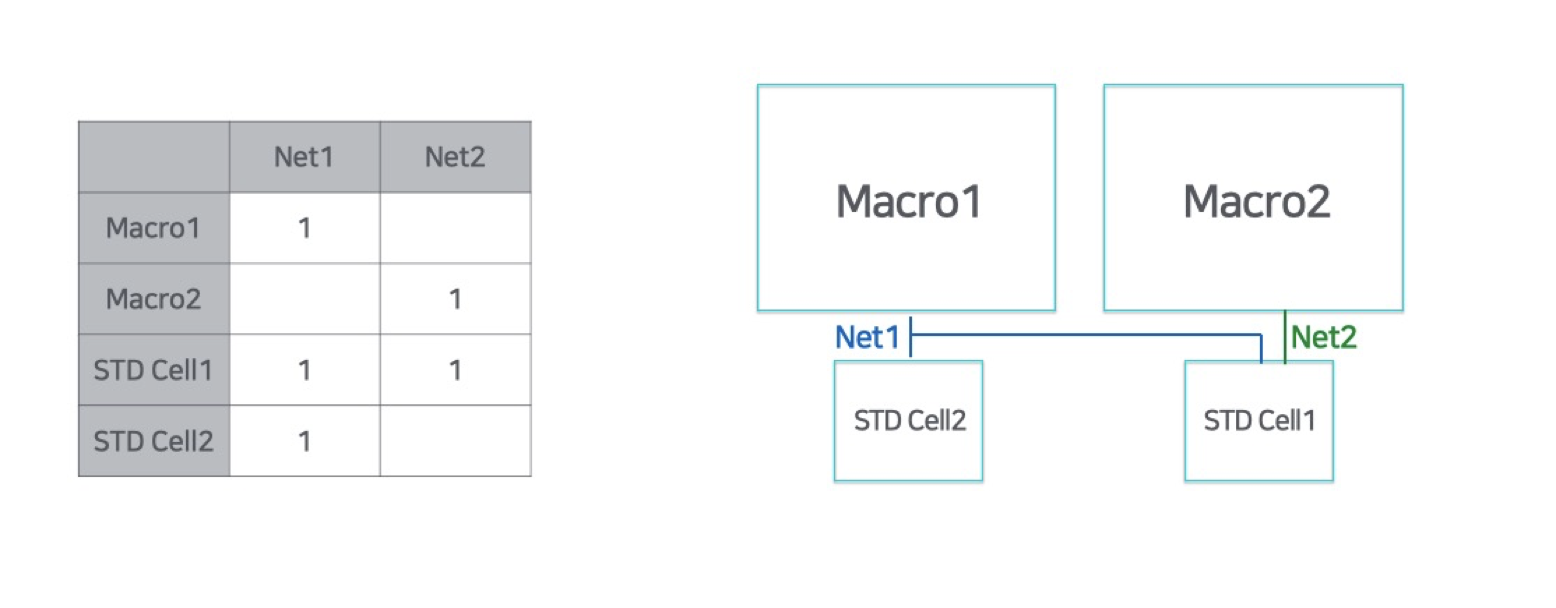 [그림2] - Netlist
[그림2] - Netlist
Netlist에 포함된 소자는 상대적으로 크기가 큰 Macro와 크기가 작은 Standard Cell로 구분할 수 있습니다. Macro는 설계를 위해 따로 만든 소자로, CPU, RAM 등이 이에 속합니다. Standard Cell은 설계속도를 높이기 위해 미리 만들어 놓은 논리소자입니다. AND, OR과 같은 논리소자들이 Standard Cell에 속하고, 일반적으로 Macro보다 매우 작고, 개수가 많습니다.
마지막으로 Physical Design 단계에서는 Netlist를 사용해 실질적으로 소자 배치합니다.
1.3 Physical Design
Physical Design 단계는 주어진 Netlist와 Macro 배치에 대한 가이드라인에 맞게 비어있는 Chip Canvas 위에 소자들을 배치하고 와이어를 연결합니다.
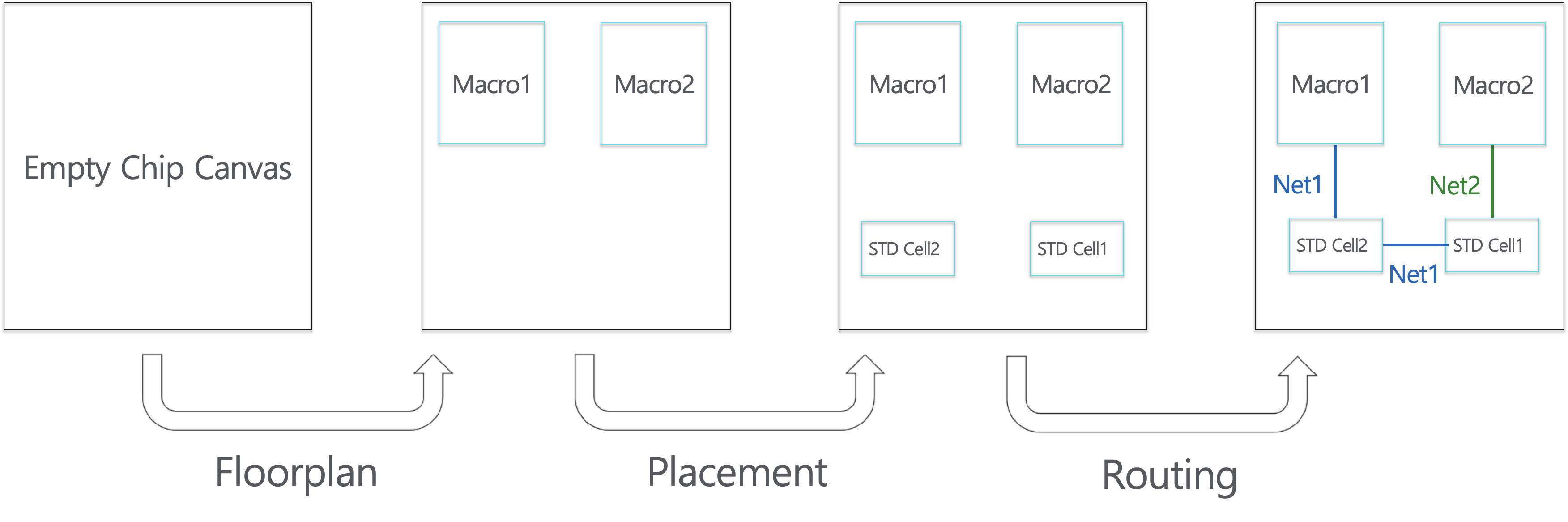 [그림3] - Floorplan
[그림3] - Floorplan
Chip Canvas란 소자들을 배치하고 와이어를 연결해 전자회로를 구성할 판을 말합니다. Physical Design은 크게 Floorplan, Placement, Routing 단계로 이루어져 있습니다
Floorplan 단계에서는 비어있는 Chip Canvas 위에 Macro를 배치합니다. Placement 단계에서는 Standard Cell을 배치합니다. Routing 단계에서는 Chip Canvas에 Wire를 통해 소자들을 물리적으로 연결합니다.
Physical Design에서 Macro를 먼저 배치하는 이유는 Macro가 Canvas 위에서 많은 영역을 차지하고, Macro 배치에 대한 가이드라인이 주어지기 때문입니다. 따라서 Macro를 먼저 배치하고 이후에 Standard Cell을 배치합니다.
Placement와 Routing 단계는 EDA(Electronic Design Automation) 툴을 사용하여 자동으로 진행합니다. EDA는 컴퓨터를 활용해 Chip Design에 도움을 주는 프로그램입니다. 국내에서 많이 사용되는 프로그램으로는 Synopsys사의 ICC2가 있습니다. Floorplan은 아직 충분한 성능과 속도를 보장하는 툴이 없으므로 주로 반도체 설계 전문가들이 수작업으로 작업을 진행합니다.
저희 COP 팀은 충분한 성능을 보장하는 Floorplan 자동화 기술을 확보하여 반도체 설계 전문가들이 수작업으로 작업을 진행하면서 겪는 불편을 해소하고자 합니다.
1.4 좋은 설계를 판단한 Metric
그렇다면 Floorplan에서 성능은 어떻게 측정할까요?
Floorplan에서 성능은 PPA(Power, Performance, Area)로 측정합니다. 일반적으로 Wire 길이가 짧아지면 PPA가 좋아집니다. Wire 길이가 짧아진다면 전기 신호의 전달이 빨라져 성능이 좋아집니다. 그리고 신호가 전달되는 길이가 짧아져서 전력 사용량은 줄어듭니다. 또한 소자들이 가까이 배치되어 집적도가 올라 낮은 면적을 차지하게 됩니다.
소자들을 가까이 배치하면 Wire 길이가 짧아집니다. 하지만 Chip Canvas의 같은 영역에 Wire를 배치할 수 있는 자원(Routing Resource)은 정해져 있습니다.
아래의 그림4 에서 왼쪽 그림은 빨간 사각형 영역의 Routing Resource를 모두 사용한 경우 입니다. (Macro 2, Standard Cell 2, Standard Cell 5)를 연결하는 Wire를 배치하는 경우를 생각해 봅시다. 빨간색 선은 이 세 소자를 최단 경로로 연결한 Wire입니다. 하지만 빨간색 사각형 영역에는 Routing Resource를 모두 사용하여 더 이상 Wire를 배치할 수 없습니다. 따라서 오른쪽 그림의 초록색 선과 같이 Wire를 우회해서 연결해야 합니다.
아래 그림처럼 Routing Resource를 초과하는 것을 Violation이라고 합니다. Violation이 발생하면 해당 영역에 더 이상 Wire를 배치할 수 없어 Wire를 우회에서 배치해야 합니다. 이와 같이 소자들을 가까이 배치했지만 Violation에 의해 오히려 Wire 길이가 길어질 수 있습니다.
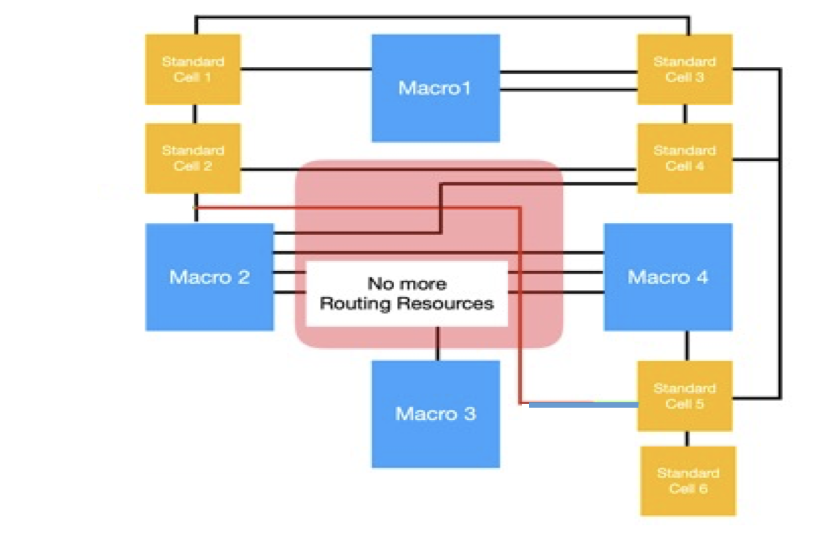
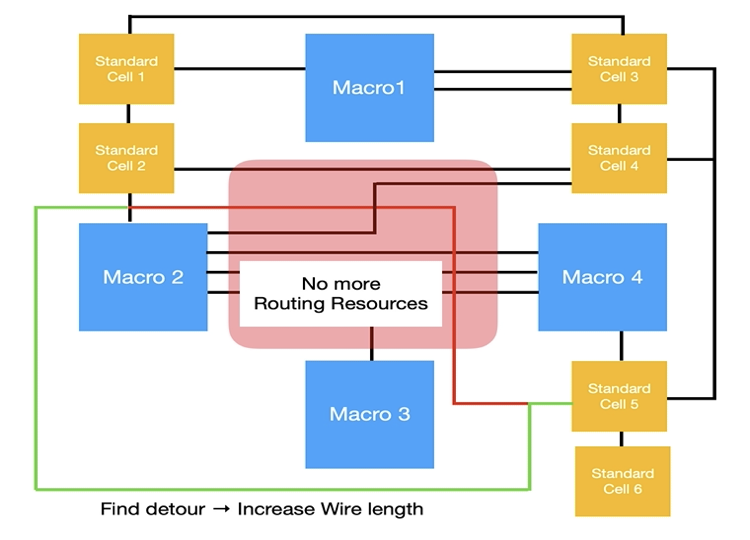
[그림4] - Before Violation(left), After Violation(right)
좋은 Floorplan은 소자들이 충분히 가까우면서 Violation이 발생하지 않게 하는 소자들의 ‘적절한 위치’를 찾는 것입니다.
1.5 Floorplan은 어렵습니다.
하지만 소자들의 ‘적절한 위치’를 찾는 작업은 어려운 작업입니다. ASIC에서 배치해야 할 Macro의 개수는 수십에서 수백 개 이상이고, 전체 소자의 개수는 수십만에서 수백만 개 이상입니다. 반도체 설계 전문가는 수십~수백 개의 소자에 대해서 수백만 개의 연결 관계를 고려해 각 소자의 ‘적절한 위치’를 찾아야 합니다.
또한 반도체 설계 전문가가 배치한 결과의 피드백 과정이 오래 걸립니다. Floorplan에 뒤잇는 설계과정은 며칠 이상의 시간이 소요되기도 합니다. 만약 최종 설계 결과의 품질이 좋지 않으면 Floorplan 과정부터 다시 수행해야 합니다.
그동안 Floorplan은 전문가의 경험과 감에 의존하기 때문에 반도체 설계 전문가의 역량에 따라 소요 시간과 설계 품질의 편차가 크게 나타납니다. 이로 인해 반도체 설계 일정 수립이 어렵습니다.
1.6 문제해결의 의의
저희는 반도체 설계 업계에 종사하는 Logic Designer와 Physical Designer 에게 Floorplan 자동화에 대해 어떻게 생각하는지 여쭈어보았습니다. Logic Designer 는 좋은 Macro 배치 가이드라인을 전달하기 편하다는 점에서, Physical Designer는 설계 시간을 단축하여 반도체 설계 전문가의 숙련도 차이에 따른 설계 편차를 줄일 수 있다는 점에서 관심을 보였습니다. 또한 두 분류의 전문가들 모두 이를 통해 기존 반도체 설계의 일정을 맞추기 어려운 부분을 해소할 수 있다는 점에서 흥미를 보였습니다.
2. 기존의 연구, 현재 트랜드
2.1 기존의 연구
현재 Floorplan 자동화는 주로 메타 휴리스틱 알고리즘을 사용하는 방향으로 접근하고 있습니다. 메타 휴리스틱 방법이란 문제의 특성에 구애받지 않고 다양한 문제에 적용가능한 휴리스틱 방법입니다. 메타 휴리스틱 방법에는 유전 알고리즘 [1], Simulated Annealing [2] 등이 있습니다.
이러한 메타 휴리스틱 알고리즘은 작은 문제에 대해서는 빠르게 좋은 성능을 낼 수 있다는 장점이 있습니다. 하지만 문제의 크기가 커질수록 좋은 성능을 내는데 필요한 시간이 매우 커지고, 언제 수렴되는지 알기 어렵다는 문제가 있습니다. 또한 소자나 Chip Canvas에 변동이 생기면 다시 메타 휴리스틱 방법을 적용하여 배치를 찾아야 합니다.
2.2 강화학습을 이용한 Floorplan
최근에는 좋은 배치를 출력하도록 뉴럴 네트워크를 ‘학습’시키는 머신러닝 기법으로 Floorplan 문제를 해결하는 움직임이 보여지고 있습니다 [3][4] 머신러닝 기법은 새로운 Netlist에 대해서 새로 학습을 진행하지 않거나 조금만 학습해도 좋은 성능을 보여줄 수 있다는 장점이 있습니다. 따라서 학습이 잘 되었다면 빠른 속도로 좋은 결과를 출력할 수 있습니다.
강화학습은 머신러닝 방법의 하나로 최적의 결과물이 아닌 결과물에 대한 성능 평가 측정치로 피드백을 주어 성능을 최대화하는 방향으로 학습하는 방법입니다. Floorplan 문제는 배치 성능을 측정하는 방법은 존재하지만, 최적의 배치를 알지 못한다는 점에서 머신러닝 기법 중에서 강화학습이 Floorplan 문제 해결에 가장 적합합니다. 따라서 Floorplan 문제를 강화학습으로 해결하는 논문들이 발표되고 있습니다.
저희도 강화학습을 활용하여 Floorplan 자동화 문제를 해결하고 있습니다.
3. What we Do?
3.1 문제 정의
COP 팀은 주어진 Netlist에 대해서 Floorplan 자동화 문제를 해결하고 있습니다.
Netlist의 크기는 ASICLand 디자인하우스의 현업자 분들과 함께 상의하여 정했습니다. 저희는 산업에서 유의미하다고 보는 복잡도의 문제를 100만 개 소자의 Netlist로 설정하였습니다. 그리고 이를 해결하기 위해 소자의 개수에 따라 단계적으로 목표를 설정하여 접근하고 있습니다.
- Toy Example: 소자 237개
- 저 복잡도 문제: 소자 122,424개
- 중 복잡도 문제: 소자 633,339개
- 고 복잡도 문제: 소자 약 1,000,000개
성능 평가 Metric은 PPA 중에 Performance를 사용합니다. PPA 중에 Area는 요구사항에 따라 미리 정해집니다. 그리고 Power는 설계 과정의 뒷단계에서 확인하므로 Physical Designer들이 하는 것과 같이 앞단에서 확인가능한 Performance로 성능을 평가합니다.
Performance는 Worst Negative Slack (WNS), Frequency와 같은 Timing Metric으로 측정합니다. Slack은 신호가 각 소자에 전달될 때 요구사항(Required Arrival Time)과 실제 도착 시간(Actual Arrival Time)의 차이를 의미합니다. WNS는 Slack 중 최솟값을 의미합니다. WNS가 0 이하면 요구된 제약조건에 대한 Violation이므로 WNS는 0 이상이어야 합니다.
Frequency는 1초당 처리할 수 있는 신호의 수, 즉 연산속도를 의미합니다. Frequency는 높을수록 좋습니다.
요약하면 문제를 다음과 같이 정의할 수 있습니다.
주어진 Netlist에 대해 0 이상의 WNS와 최대한의 Frequency를 갖는 Macro 배치를 찾는 문제
이번 포스팅에서는 저복잡도 문제에 대한 실험 결과를 공유하겠습니다. 저 복잡도 문제는 비교적 단순한 문제로 유의미한 성능 비교를 하기 어렵습니다. 하지만 저 복잡도 문제를 해결함으로써 저희가 개발한 Placer의 타당성을 증명하여 이후 중 복잡도, 고 복잡도에 해당하는 문제를 해결할 수 있다는 가능성을 보여주었습니다.
3.2 시도한 방법
COP 팀이 개발한 Placer는 다음과 같습니다.
 [그림5] - Placer
[그림5] - Placer
배치해야할 소자의 개수는 약 12만개로, 모든 소자를 강화학습으로 일일이 배치하기 어렵습니다. 따라서 Standard Cell들을 Clustering하고 하나의 Cluster를 하나의 소자처럼 취급하여 문제의 크기를 축소시킵니다.
Clustering 이후 Netlist에 있는 소자 간의 연결 관계 정보와 Canvas 위에 배치된 소자들의 배치 정보를 뉴럴 네트워크를 활용해 Embedding 합니다. 강화학습 Agent는 Embedding 된 값을 기반으로 다음 소자를 어디에 배치할지 결정합니다. 마지막 소자가 배치되었을 때 Reward를 계산하여 뉴럴 네트워크를 학습합니다. 학습이 끝나면 가장 높은 Reward를 갖는 Macro 배치 정보를 출력합니다.
학습 결과는 실제 반도체 설계 전문가가 작업하는 흐름에 따라 검증합니다. 반도체 설계 전문가는 Floorplan의 성능을 검증할 때 시간 등의 이유로 Placement 이후 요구사항에 맞게 소자들의 배치를 재조정하는 Placement Optimization까지 수행 후 성능을 측정합니다. 이후 Violation이 발생하지 않고 WNS와 Frequency에서 합리적인 결과가 나왔다면 이후 과정을 진행합니다. 그렇지 않다면 Floorplan 과정부터 다시 진행합니다. 저희도 마찬가지로 Placement Optimization까지 수행 후 WNS와 Frequency를 측정하여 Floorplan을 평가하였습니다.
3.3 실험 결과
디자인하우스의 반도체 설계 전문가의 Floorplan 진행 상황을 관찰할 때 Standard Cell들 간의 연결성이 강하기 때문에 Standard Cell을 Canvas 중앙에, Macro를 Canvas의 외곽 쪽에 배치하는 경향성을 확인할 수 있었습니다.
이러한 관찰에 따라 첫 번째 시나리오에서는 Macro와 Standard Cell의 배치 위치에 제약사항을 주었습니다. 이후 시나리오에서는 제약사항을 하나씩 제거하며 학습의 난이도를 점진적으로 높였습니다.
- Single Cluster + Bounding Box: 첫 번째 시나리오는 Standard Cell을 하나의 Cluster로 가운데에 배치하고, Macro는 입출력 포트를 제외한 가장자리 영역에만 배치할 수 있도록 하는 경우입니다.
- Multiple Clusters + bounding box : 두 번째 시나리오는 첫 번째 시나리오에서 Standard Cell을 단 하나의 Cluster로 표현하는 것과 달리 여러 개의 Cluster로 표현하며 이를 강화학습 Agent가 직접 배치합니다. 다만, Standard Cell과 Macro에 별도의 배치 영역을 할당해, Macro는 가장자리에만, Standard Cell은 Canvas 전 영역에 배치할 수 있도록 했습니다.
- Non-Heuristic: 세 번째 시나리오는 별다른 휴리스틱 없이 강화학습 Agent가 Macro와 Standard Cell을 Canvas 전 영역에 배치하는 경우입니다.


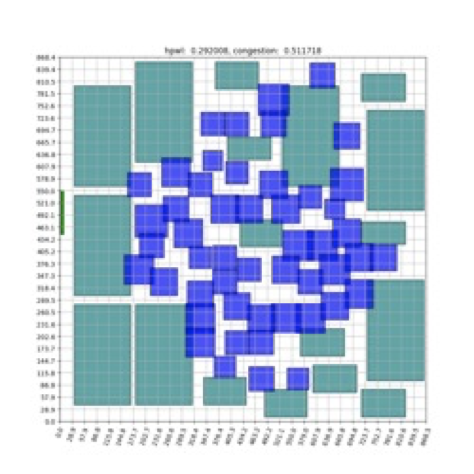
[그림6] - 1) Single Cluster + Bounding Box, 2) Multiple Cluster + Bounding Box, 3) Non-Heuristic
개발한 Placer는 디자인하우스의 반도체 설계 전문가와 ICC2 툴에서 Macro를 자동으로 배치해주는 Macro Auto Placement 기능과 비교했습니다. 실험 결과 강화학습 Placer는 반도체 설계 전문가와 Macro Auto Placement 기능과 비슷한 성능을 보여주었습니다.
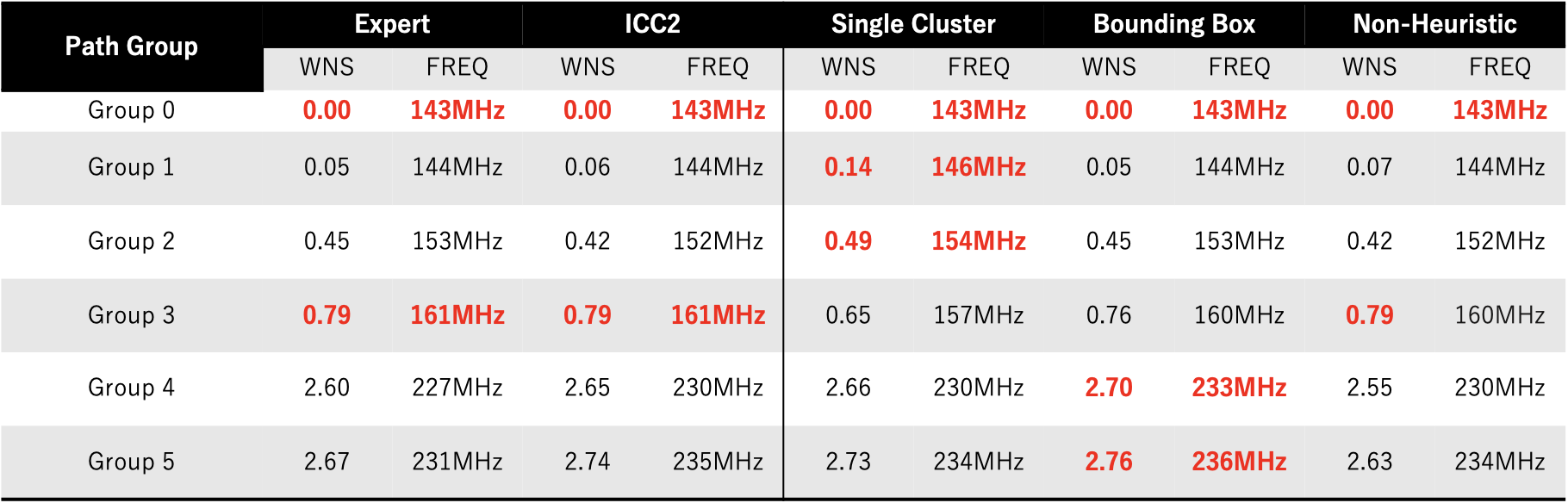 [그림7] - Experimental Result
[그림7] - Experimental Result
4. 결론
소 복잡도 Netlist에 대해서 개발한 Placer가 잘 동작하는지 확인하였습니다. 앞으로는 확보한 Cell 60만 개, 100만 개 크기, 그리고 그 이상의 Netlist에서의 Floorplan 자동화 문제를 해결하고자 합니다. 그리고 새로운 Netlist에 대해서 최소한의 추가 학습으로 배치 문제를 해결하고자 합니다.
또한 Floorplan 문제를 해결하면서 확보한 강화학습과 조합 최적화 문제에 관한 기술을 활용해 물류 거점 최적화, 생산설비 최적화 등의 조합 최적화 문제에 확장하여 적용할 예정입니다.
이번 포스팅에서는 ASIC Design 과정에서 Floorplan 자동화가 필요한 이유에 관해서 이야기했습니다. 또한 COP 팀이 Floorplan 자동화 문제를 해결하는 과정에서 현재 어떤 지점에 있는지 소개하였습니다. 다음 포스팅에서는 COP 팀이 Floorplan 자동화 문제를 어떻게 해결하였는지 구체적인 내용을 말씀드리도록 하겠습니다.
Reference
[1] Henrik Esbensen, 1992, A Genetic Algorithm for Macro Cell Placement.
[2] S. Kirkpatrick, C. D. Gelatt, Jr., M. P. Vecchi, 1983, Optimization by Simulated Annealing.
[3] Azalia Mirhoseini, Anna Goldie, Mustafa Yazgan, Joe Jiang, Ebrahim Songhori, Shen Wang, Young-Joon Lee, Eric Johnson, Omkar Pathak, Sungmin Bae, Azade Nazi, Jiwoo Pak, Andy Tong, Kavya Srinivasa, William Hang, Emre Tuncer, Anand Babu, Quoc V. Le, James Laudon, Richard Ho, Roger Carpenter, Jeff Dean, 2021, A graph placement methodology for fast chip design.
[4] Google AI, 2020, Chip Placement with Deep Reinforcement Learning, Google AI Blog.