


안녕하세요. 마키나락스의 김제민입니다.
강화학습에 있어서 긴 학습시간은 project의 bottle neck으로 다가오며, 이에 대한 개선은 실 project를 진행하는데 있어 매우 중요한 요소로 작용합니다. 본 블로그에서는 PPO 학습 시간을 단축하기 위해 필요한 PPO 분산처리에 대해서 다뤄보도록 하겠습니다.
PPO(Proximal Policy Optimization)
- Proximal Policy Optimization (PPO), which perform comparably or better than state-of-the-art approaches while being much simpler to implement and tune. ( from OpenAI )
- TRPO(Trust Region Policy Optimization)는 학습중 policy 의 성능을 떨어뜨리지 않는 범위에서 최대한의 성능 개선을 이룰수 있는 이론을 제시하였습니다.
- PPO는 Cliped Objective를 사용하여 TRPO 알고리즘의 복잡한 계산과정을 효율화시킨 알고리즘이라고 볼 수 있습니다.
- PPO 에 대한 보다 자세한 정보를 얻고자 한다면 다음을 참고하십시오.
- PPO paper : https://arxiv.org/abs/1707.06347
- TRPO paper : https://arxiv.org/abs/1502.05477
- Open AI spinning up : https://spinningup.openai.com/en/latest/algorithms/ppo.html
PPO 학습 과정 및 분산 처리
- PPO 학습은 다양한 방식으로 가능 하지만, 해당 논문(arXiv:1707.06347)에서는 길이 T 의 fixed-length trajectory segment들을 수집하여 학습 하는 방식을 제안하고 있습니다. 이때 T 는 episode length 보다는 작은 값은 선택하게 됩니다.
- trajectory segment 는 N개의 actor ( 강화 학습 환경 + agent) 에서 수집되며, 이렇게 수집된 N개의 trajectory segment를 학습에 사용합니다.
- 수집된 trajectory 는 NT timestep이 존재하며, 최종적으로 이를 size M의 mini-batch 형태로 K epoch 만큼 학습을 수행합니다. (M ≤ NT)
- 위 내용을 정리하면 다음과 같습니다. ( from arXiv:1707.06347 )

- PPO 학습 과정을 분산 처리 관점에 생각해 본다면, 크게 2가지 측면을 생각해 볼 수 있습니다.
- trajectory 수집의 분산처리
- 학습과정을 보면 N개의 actor에서 trajectory segment 를 수집하게 되므로, 각 actor들을 독립적으로 실행하여 trajectory 수집을 동시에 수행한다면, trajectory segment 수집 과정은 이론적으로 N배가 빨라짐을 알 수 있습니다.
- SGD 의 분산 처리
- neural net 모델의 크기가 크다면, SGD 를 분산 처리함으로써 학습 시간을 단축할 수 있습니다.
- trajectory 수집의 분산처리
- 2가지 방식의 분산 처리를 모두 고려해 볼 수 있지만, 일반적으로 강화학습 소요 시간중 trajectory 수집이 차지하는 비중이 굉장히 큰 관계로, trajectory 수집의 분산 처리만으로도 충분한 학습속도 개선을 이룰 수 있습니다.
- 본 블로그에서는 trajectory 수집의 분산 처리에 대해서 다룹니다.
분산 PPO 구현시 고려사항
- 분산 PPO 구현에 있어서는 크게 2가지 component를 생각해볼 수 있습니다.
- Learner
- Actor들로 부터 trajectory를 수집해서 실제 학습이 이루어 집니다.
- 전체 학습과정의 master 역할을 하게 되며, trajectory 수집 이외에, actor의 모델을 learner의 모델과 sync 하는 역할도 수행합니다.
- Actor
- 강화 학습 환경 + agent
- 실제 PPO Agent가 강화 학습 환경에서 실행되며, trajectory 를 생성합니다.
- Learner의 요청을 받아 trajectory segment 를 생성하며, Learner 에 의해서 model 이 update 됩니다.
- Learner
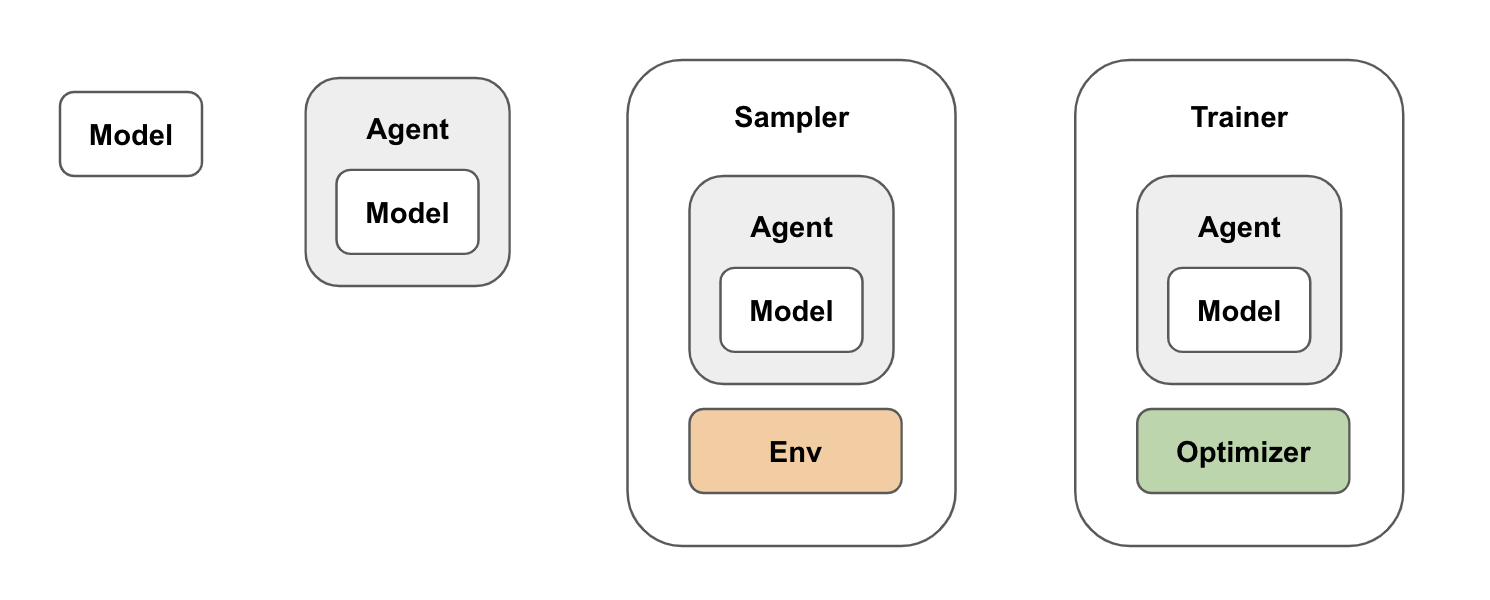
- 이렇게 Learner , Actor 형태로 구현하기 위해서는 PPO algorithm 을 기능에 따라 모듈화를 할 필요가 있습니다.
- PPO Model : neural net 모델
- PPO Agent : PPO RL agent
- PPO Sampler : trajectory 수집
- PPO Trainer : neural net 학습
- 다음으로는 분산 처리 구현을 위해, ray library 에 대해서 다뤄 보겠습니다.
ray 소개
- ray는 분산 object 및 이들 사이의 data communication을 매우 쉽게 구현 할 수 있는 library 를 제공합니다. 본 블로그에서는 간단한 ray 예제를 다뤄보면서, PPO 분산처리에 대한 이해를 돕고자 합니다.
- ray 에 대한 보다 자세한 내용은 다음을 참조하십시오.
- ray doc : https://docs.ray.io/en/latest/
- 예제
import ray ray.init() @ray.remote class Accumulator(object): def __init__(self,n): self.n = n def increment(self,v): self.n += v def read(self): return self.n accumulators = [Accumulator.remote(i) for i in range(4)] [acc.increment.remote(2) for acc in accumulators] futures = [acc.read.remote() for acc in accumulators] print(ray.get(futures)) # [2, 3, 4, 5]- ray cluster 접속
- ray remote 기능을 사용하려면, ray cluster 에 접속을 해야 합니다.
ray.init()
- ray remote 기능을 사용하려면, ray cluster 에 접속을 해야 합니다.
- remote class instance(ray actor)
-
- class를 worker node 에서 remote 로 생성하려면, @ray.remote decorator 를 사용합니다.
@ray.remote class Accumulator(object): ...- remote class 생성 및 remote method call 은 .remote 를 추가해서 호출합니다.
acc = Accumulator.remote(3) # remote class (ray actor) 생성 future = acc.increment.remote(2) # remote method call
-
- future
- remote function call 의 결과는 future 로 반환 됩니다.
future = acc.increment.remote(2)
- future 의 실행 완료를 기다리기
ray.wait(future)
- future의 결과 값을 가져오기
ray.get(future)
- remote function call 의 결과는 future 로 반환 됩니다.
- ray cluster 접속
분산 ppo ray 구현 예( pseudo code)
- ray 를 이용하여 pseudo code 형태로 분산 PPO 를 구현해 보겠습니다.
- PPOActor
class PPOActor(object): ... def get_trajectory_segment(self) -> PPOTrajectorySegment: ... def set_model(self,model) ... - PPOLearner
class PPOLearner(object): ... def train(self,segments: List[PPOTrajectorySegment]): ... def get_model(self): ... - runner
PPOActorRemote = ray.remote(PPOActor) def run(num_of_actors): ray.init() learner = PPOLearner() actors = [] for i in range(num_of_actors): actor = PPOActorRemote() actors.append(actor) model = learner.get_model() futures = [actor.set_model.remote(model) for actor in actors] ray.wait(futures, num_returns=len(actors)) while True: segments_future = [actor.get_trajectory_segment.remote() for actor in actors] ray.wait(segments_future, num_returns=len(actors)) segments = ray.get(segments_future) learner.train(segments) model = learner.get_model() futures = [actor.set_model.remote(model) for actor in actors] ray.wait(futures, num_returns=len(actors))
학습 시간 비교 ( 8-distributed vs single)
- x-axis : time
- y-axis : episode reward
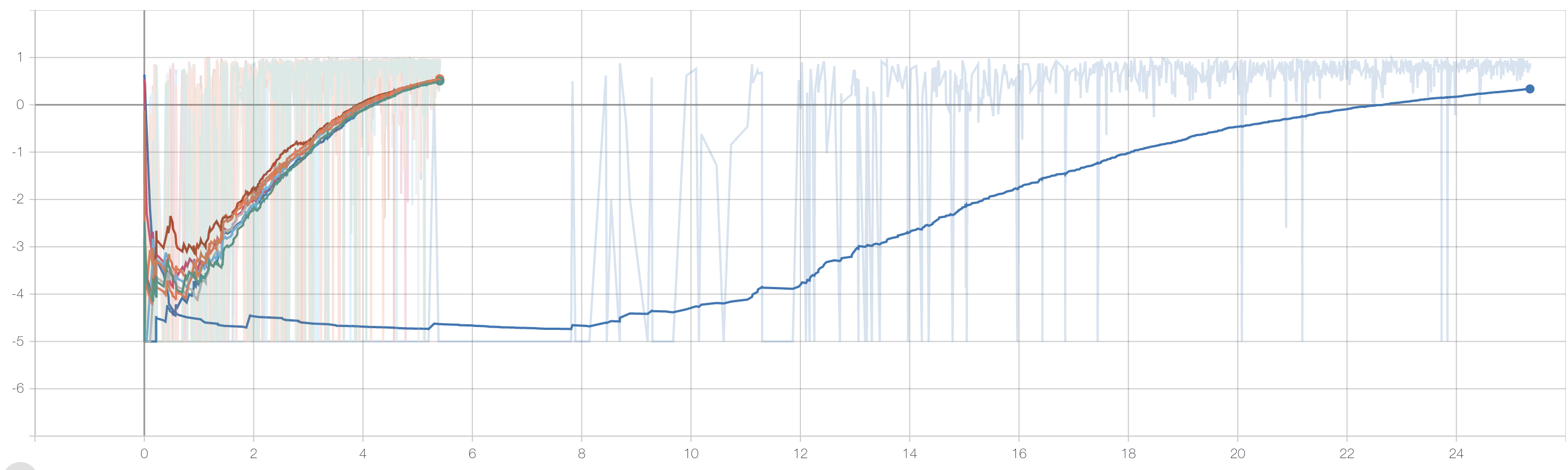
- 8개의 actor 로 학습한 실험과 1개의 actor로 학습한 실험의 실행 결과 비교 그래프입니다.
- 그래프상 왼편에 distributed actor들의 그래프를 볼 수 있으며, 청색의 그래프는 single actor입니다.
- 분산 처리를 한 경우 확연한 학습 시간 감소를 확인 할 수 있습니다.
맺음말
이렇게 ppo의 분산처리 구현에 대해서 다뤄 보았습니다.
본 블로그에서는 분산처리 중 trajectory 수집의 분산처리 측면을 다루었습니다. 그렇지만, 모델이 크기가 커질 경우에는 분산 SGD 에 대해서도 고려해 볼 필요가 있습니다.
다음 기회에는 모델의 분산 학습에 대해서도 다뤄 보도록 하겠습니다.
» 이 글은 마키나락스 미디엄에 게재된 포스팅으로 원문은 여기서 확인하실 수 있습니다.














