
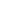
The real-world AI we envision holds immense promise, offering opportunities for innovation and transformation. However, turning this promise into reality is far from easy. While many companies attempt to adopt AI, only 16% of global manufacturing organizations have achieved their AI-related targets. Bringing AI into the real world requires overcoming significant hurdles before it can truly drive business impact. So, what makes real-world AI so challenging? Here are the key reasons behind these difficulties.
Go is known for its immense complexity, with an estimated 10170 possible outcomes. But the real world is far more complex than a Go board. AlphaGo was trained on high-quality, publicly available games played by world-class players, refining its performance through infinite repetitions. While its capabilities are assured within the confined space of a Go board against a single opponent, the real world introduces countless variables, and accessing all the high-quality data is fundamentally unattainable.
Take the complexity of a manufacturing floor as an example. Variables like temperature, humidity, noise, equipment wear, and scheduling all interact, influencing machine performance and even the timing of part replacements. Additionally, variations in worker skills and changing conditions add to the dynamic nature of the production environment. This complexity is far beyond what AlphaGo was designed to handle. But what if there were an AI specifically built to tackle such challenges—trained on diverse variables and data in an environment that mirrors the intricacy of an industrial workplace?
🔗 Connecting industrial sites in real time with AI digital twin
Autonomous driving is often regarded as the pinnacle of real-world AI. Yet, despite hundreds of billions of dollars invested over the past decade, full Level 5 automation—where vehicles perform all driving tasks in any condition without human intervention—remains elusive. A major limitation of AI lies in its inability to perform reliably in unforeseen scenarios or when faced with completely new data outside its training.
Even the best-performing AI models developed in a controlled lab environment can falter when deployed in the unpredictable real world. To ensure consistent performance, AI must be continuously updated with fresh data—a process known as continuous training (CT). However, relying on humans for this process is neither scalable nor practical. Automating continuous training is essential for enabling AI to adapt and thrive in unpredictable real-world environments.
🔗 Real-World AI: Runway, an AI platform enabling automated operational environments
 Who knows the factory better—ChatGPT or a 20-year veteran?
Who knows the factory better—ChatGPT or a 20-year veteran?
In industrial settings, ChatGPT is comparable to a senior at Stanford University. Imagine placing this highly capable student in a California factory. Could they perform well from day one? Likely not. They'd first need to figure out what to do—learning the names of the equipment, understanding the variables for optimal control, and identifying the right people to seek help from.
By contrast, a veteran worker with 20 years of experience at the same factory could solve these problems in minutes. Years of hands-on knowledge and domain expertise enable them to quickly identify and solve problems, demonstrating the immense value of on-site experience.
While ChatGPT can generate human-like text, images, and code, it cannot function effectively in industrial environments without access to industry-specific data. The challenge? Industry data is proprietary and tightly guarded, with companies rarely sharing it externally. Without this critical data, ChatGPT cannot deliver the level of performance required for such settings. This is why experience with industry-specific data is crucial. The better an LLM understands the complexity of industrial processes, their unique requirements, and the data collected from various equipment and facilities, the more effectively it can be fine-tuned.
🔗 Why large language models are the future of manufacturing
In the digital world, general-purpose AI has made remarkable strides, from generating content like articles, images, and videos, to providing personalized recommendations. These systems don’t need a high degree of accuracy because their outputs can be partially referenced and adapted. Real-world AI, however, operates under entirely different conditions—it is highly specialized, tackles critical problems, and demands near 100% accuracy.
For example, if an AI fails to detect a defect during quality inspection, defective products may reach customers, causing dissatisfaction, costly recalls, and damage to the company’s reputation. Errors on production lines can also lead to massive rework and significant financial losses. In the real world, AI must respond instantly to environmental changes. If it doesn’t analyze data in real-time to adjust machine settings like temperature and pressure, the production process may be disrupted, or product quality compromised. High accuracy isn’t optional—it’s essential.
🔗 Real-world AI: AI Use cases that solve problems on the industrial floor
The real world is complex, uncontrollable, and unpredictable, with data that is difficult to access. It also demands extremely high accuracy. Despite these challenges, MakinaRocks is tackling intricate industrial problems with its compound AI system, bringing real-world AI to life. Our solutions have proven to achieve success rates more than four times higher than the global average for AI adoption.
If you’re ready to explore how AI can transform your operations, let’s start the conversation. Share your challenges by clicking the banner below, and together, we’ll uncover the best way to bring real-world AI to your business.

On the runway, models elevate the value of clothes. On MakinaRocks’ enterprise AI platform, Runway, AI models elevate the value of enterprise data. At the core of this transformation is the Runway Delta team—a group of experts dedicated to delivering the full value of Runway to customers. As the frontline champions of our AI platform, they ensure Runway is more than a product but a tailored solution to solve unique business challenges.
This cross-functional team bridges the gap between technical implementation and real-world application. By deploying and customizing Runway, they empower businesses to embed AI capabilities and unlock the full potential of their enterprise resources. Let’s take a closer look at the team and the incredible work they do.

Our team focuses on three key areas to deliver value. First, we deploy and customize Runway, tailoring the platform to address each customer’s unique challenges and deliver meaningful results. Strong communication is also vital. By understanding customer needs, gathering feedback, and delivering timely solutions, we ensure our work aligns with their goals.
We also support customers in fully adopting Runway through installation and training. This enables them to solve problems effectively and internalize AI capabilities for long-term success. Every customer faces distinct challenges, and we adapt to their specific needs to help them achieve their objectives. At the same time, insights from the field guide us in refining and improving Runway, ensuring it continues to deliver even greater value.

The Runway Delta team consists of seven members, each playing a crucial role in delivering the value of Runway to our customers. Their roles include Product Manager, Solution Engineer, and Product Technical Trainer. Here’s what each role entails:
Product Manager (PM): Oversees stable deployment of Runway and drives product improvements based on customer feedback. PMs engage directly with customers to analyze requirements, propose solutions, and address business challenges.
Solution Engineer (SE): Installs and verifies Runway for smooth operation at the customer’s site. SEs bring expertise in infrastructure, DevOps, and technical systems to handle deployments seamlessly.
Product Technical Trainer: Designs and delivers training sessions to help customers understand and maximize Runway’s features. This role requires strong organizational skills and attention to detail.
What makes a successful Runway Delta team member?
First and foremost, you need to enjoy working with customers. The Runway Delta team thrives on building strong relationships, making rapport-building skills essential. From the first meeting to the successful use of our product, connecting with customers ensures the job is both impactful and rewarding.
Another key skill is understanding and bridging gaps. Customers and team members often perceive challenges differently. That’s where the Runway Delta team shines—identifying customer needs, crafting scenarios, and demonstrating how our product effectively solves specific challenges.
Equally important is the ability to generalize specific requirements. Each customer has unique needs, but distilling these into generalized solutions allows us to serve a broader range of clients. Strong documentation skills are also critical. Well-organized deliverables at the end of each project ensure transparency and continuity while contributing to a growing knowledge base for the team.
How are these skills applied at work? Do you have a most memorable project?
We recently worked on a project with the Korea Insurance Development Institute, where we built an AI system using Runway to identify and manage automobile accident photo information. As part of the project, we also replaced their existing AI platform and customized Runway to better suit their needs.
At the end of the project, the client praised both Runway’s capabilities and Gyuseon’s leadership in managing the effort. Sharing that feedback with the entire company was a proud moment—not just for the Runway Delta team, but for everyone at MakinaRocks.
Behind the scenes with the Runway Delta team: A look at their work culture

A Runway Delta team meeting where ideas and opinions are shared openly.
Autonomy with accountability
Team members enjoy autonomy paired with a strong sense of accountability. Everyone is empowered to make decisions, but collaboration is key when challenges arise. Asking for help and working together ensures problems are resolved efficiently, leveraging the team’s collective strengths.
Team success equals individual success
We believe the success of the team is the success of each individual. When someone faces challenges, teammates step in to support and resolve issues quickly. We also create reusable templates and documentation that enhance productivity and efficiency for future projects.
Open and horizontal communication
We foster a culture where suggestions are encouraged, and discussions happen openly. Weekly meetings are a space to share project updates, address challenges together, and brainstorm new ideas. This open communication ensures that every team member’s voice is heard and contributes to our collective growth.
Transparent information sharing
To keep everyone aligned, we use public Slack channels and emails, ensuring no one is left out of the loop. At MakinaRocks, we value the use of shared spaces over private messages to keep communication clear, simple, and accessible. This approach reinforces collaboration and strengthens team-wide transparency.
Can you tell us the top 3 things you like about the Runway Delta team?
The Delta team is incredibly diverse, with each member bringing unique strengths, personalities, and experiences. We have a mix of MBTIs, ages, careers, and backgrounds, creating a lively and cheerful atmosphere. One memorable moment was when a team member shared their love of flowers, leading to an impromptu flower-shopping trip during a coffee break. These small, spontaneous moments highlight the fun and dynamic nature of our team, which currently consists of six men and one woman. Sometimes, I take on the role of a mentor; other times, I’m a supporter or simply a friend. While there’s so much I could say about what makes this team special, here are three key highlights:
On the flip side, what’s one of the challenges of being part of the Runway Delta team?
As a team that frequently interacts with customers, we travel often. Some destinations are farther than expected, and meeting new clients in unfamiliar places can sometimes be challenging. But instead of seeing travel as a stressor, we’ve turned it into a chance for fun—what we call “restaurant hopping.”
Rather than dwelling on the difficulties of being on the road, we get excited about trying local food, turning each trip into a mini culinary adventure. We even have a dedicated Delta team food channel where we share photos and honest reviews of the restaurants we’ve visited, making travel something to look forward to.
Next week, we’re heading to Yeongcheon in Gyeongsangbuk-do to meet with the Gyeongbuk Hybrid Technology Institute—and we’re already looking forward to their famous Korean street food and fresh beef tartare.
What are the future plans and goals of the Runway Delta team?
As our customer base grows, managing every case directly is becoming challenging for our limited team. To address this, we’re building partnerships with third parties and creating reusable templates to ensure consistent, high-quality results. We’re also focusing on automation to streamline workflows. Recently, we reduced Runway’s installation verification process from 24 hours to just 0.5 hours—a significant boost in efficiency. These ongoing efforts reflect our commitment to operational excellence.
Our mission is to help customers fully leverage Runway in their unique environments. From understanding needs to designing solutions, installing the product, and providing tailored training, our Product Managers, Solution Engineers, and Product Technical Trainers work together to deliver a seamless and impactful experience. By fostering collaboration and improving processes, we ensure Runway delivers exceptional value and empowers customers to thrive.
Driving innovation with the Runway Delta team
 A behind-the-scenes shot capturing the relaxed and lively atmosphere of the Runway Delta team.
A behind-the-scenes shot capturing the relaxed and lively atmosphere of the Runway Delta team.
Through this glimpse into the Runway Delta team, it’s clear how passionate, positive, and committed they are to understanding customer needs and solving challenges. Their pride in collaborating with clients, applying AI to drive meaningful outcomes, and embracing their responsibilities with enthusiasm is truly inspiring.
The Runway Delta team is more than a provider of an AI platform—they are true partners, working alongside customers to create tailored solutions that deliver real value. As they continue to grow and innovate with their clients, we look forward to witnessing the meaningful impact they’ll create in the years ahead.
Can AI outperform humans? For years, this question remained unanswered—until 2016, when AlphaGo made history by defeating Lee Sedol. AlphaGo, an AI program developed by Google DeepMind, utilized deep learning and reinforcement learning to master the complex game of Go. In March 2016, it triumphed over South Korean 9-dan professional Go player Lee Sedol, winning 4 games to 1, demonstrating the true potential of AI to the world.
Go is known for its immense complexity, with an estimated 10170 possible outcomes—more than the number of atoms in the universe. AlphaGo, leveraging vast computational power, learned and refined its strategy in real time. However, the Go board is a highly controlled environment, with all variables known and finite. In such a setting, AlphaGo’s victory was almost inevitable.
But the real world is far more complex than a Go board. AlphaGo was trained on high-quality, publicly available games played by world-class players, refining its performance through infinite repetitions. While its capabilities are assured within the confined space of a Go board against a single opponent, the real world introduces countless variables, and accessing all high-quality data is fundamentally unattainable.
Take the complexity of a manufacturing floor as an example. Variables like temperature, humidity, noise, equipment wear, and scheduling all interact, influencing machine performance and even the timing of part replacements. Additionally, variations in worker skills and changing conditions add to the dynamic nature of the production environment. This complexity is far beyond what AlphaGo was designed to handle.
What if AI could handle the unpredictable environments of industrial sites? Unlike AlphaGo, which operates in a structured game setting, AI trained on real-world data can learn to manage a broad range of variables. In industry, the ongoing challenge is maximizing efficiency and productivity. However, applying AI directly to functioning processes carries risks.
Industrial sites are intricate systems where countless variables interact. If AI models aren’t rigorously validated in real-world scenarios, they could fail unpredictably, potentially interrupting processes or compromising product quality. That’s why a cautious, methodical approach is crucial when implementing new technologies like AI. Testing AI in real-world environments without proper simulation is impractical and risky.
AI-powered digital twins simulate real-world complexities, allowing companies to test AI models in a risk-free environment before live deployment. MakinaRocks has developed its own multi-step simulation dynamics model, creating a digital twin that replicates industrial environments, including processes, equipment, products, and operational conditions. This enables rapid validation and optimization of AI models for tasks like prediction, optimization, and predictive maintenance, ensuring safer innovation without disrupting current operations.
 Illustration of MakinaRocks’ AI-powered digital twin
Illustration of MakinaRocks’ AI-powered digital twin
In the industrial world, AI-powered digital twins are transforming productivity, operational efficiency, and risk management. While traditional equipment simulators provide valuable insights, they often fall short of capturing real-time changes in process conditions. MakinaRocks’ digital twin overcomes this limitation by offering real-time monitoring of both equipment and process conditions, as well as external factors and operator behavior. This creates a highly accurate and dynamic simulation.
Unlike basic simulators that predict only the next step (single step), MakinaRocks’ digital twin can forecast mid- to long-term (multi-step) state changes, offering a deeper understanding of future developments. By incorporating observation variables, internal and external conditions, and control inputs from real industrial data, the digital twin enables testing of multiple control scenarios. Combined with advanced AI models, this technology effectively addresses complex industrial challenges such as preventing critical failures, optimizing control systems, and improving production schedules.
How are digital twins transforming industries? Let’s look at a practical example in 🔗 energy efficiency for an electric vehicle's air conditioning system. By providing current state data, target temperature, and desired energy efficiency, a reinforcement learning agent calculates control values for the system’s actuators. These values are then fed into the AI-powered digital twin, which simulates the predicted temperature and energy efficiency. The results are compared to the target, and the agent is rewarded based on how closely the goals are met. Through continuous feedback, the agent optimizes control values, ultimately achieving the desired temperature and efficiency.
Beyond electric vehicle air conditioning, MakinaRocks has applied this approach across multiple domains, including 🔗 tuning parameters of industrial machines, 🔗 optimizing temperatures in steel furnaces, and automating waste incinerator operations. In fact, more than 5,000 AI models deployed by MakinaRocks are being validated and used in real-world digital twins, providing precise, AI-driven insights that mirror actual conditions.
Curious about how to leverage AI for real business impact in the complex, unpredictable industrial landscape? Click the banner below to contact us. We’re here to help you turn possibilities into reality.
At MakinaRocks, we believe AI can make the world a better place. Its innovations will extend far beyond office productivity and digital environments. We see AI creating unprecedented advancements in the real world, where we breathe, move, and interact.
In the vast expanse of the real world, we harness AI to intelligentize industrial sites. With endless streams of industrial data from countless machines, we solve complex challenges and drive real business impact. The industrial floor is constantly evolving, and the challenges are becoming tougher. We break new ground in this complex and unpredictable environment with industry-specific AI.
What lies ahead for real-world AI? At its core, AI is a technology designed for people. It rapidly and accurately solves real-world problems while also uncovering new solutions that humans might not envision. Real-world AI is about harmonizing people and technology to build a better world. We’re creating a future where the industrial workspace is intelligent, allowing people to focus on what they do best.

General-purpose AI like ChatGPT enhance office productivity by translating, writing, coding, and more in digital environments. Fashion e-commerce platforms and content platforms offer personalized recommendations. It’s almost impossible to navigate the digital world without AI. But what about the economic implications in the real world? According to the World Bank, the digital economy contributes over 15% of global gross domestic product (GDP). While the digital economy is rapidly expanding, the physical world still constitutes the majority of the global economy. We believe AI will have an even greater impact when applied to these vast markets. AI has the potential to revolutionize industries such as automotive, robotics, semiconductors, batteries, energy, logistics, and more.
The value of AI in real-world industries is immense. For instance, in manufacturing, AI can enhance demand forecasting, enabling logistics to optimize inventory management and delivery planning. This leads to faster delivery times and cost reductions. Retailers can also optimize inventory and plan sales promotions based on AI-driven demand forecasts. As AI applications in manufacturing increase, IT companies will develop new solutions and services to support them, driving further R&D investment and technological advancements.

The potential of real-world AI is just the tip of the iceberg. AI and data are intrinsically linked; AI needs data to function, and data determines AI’s effectiveness. In the digital world, vast amounts of online data can be easily collected and analyzed at relatively low costs. But what about the real world?
Look around your surroundings. We generate massive amounts of data daily. Home appliances, vehicles, daily routes, and objects we use all produce data. AI can analyze this data to make our lives more efficient, solve unpredictable problems, and unlock new possibilities.
In industrial environments, machines continuously generate data such as vibrations, temperatures, and sounds. A well-designed AI system comprehends the physical laws and context of this data. It can recognize real-time events on the industrial floor and control physical elements like equipment and robots. AI is redefining automation from rule-based tasks to intelligent operations. However, obtaining high-quality, consistent data remains a significant challenge. There is a wealth of untapped data in the real world, and harnessing this data can unleash AI’s full potential.
Interested in exploring the new horizons of real-world AI, with its vast markets and immense potential? Stay tuned for the next installment of our series, where we’ll showcase how we’re making real-world AI a reality with enterprise customers across various industries, including automotive, semiconductor, battery, chemical, defense, retail, and utilities. In the meantime, if you’d like to discuss real-world AI for your organization, click the banner below to reach us. We’re here to help.
Hello, we are Seokgi Kim and Jongha Jang, AI engineers at MakinaRocks! At MakinaRocks, we are revolutionizing industrial sites by identifying problems that can be solved with AI, defining these problems, and training AI models to address them. Throughout numerous AI projects, we have recognized the critical importance of experiment management. This insight was particularly highlighted while working on an AI project for component prediction with an energy company. Our experiences led us to develop and integrate a robust experiment management function into our AI platform, Runway. In this post, we’ll share how we systematized our experiment management approach and our learnings from various AI projects.
The core of any AI project is the performance of the models we develop. Improving model performance requires a structured approach to conducting and comparing experiments. When developing models, we often test various methods by individual team members. It's crucial that these experiments are conducted under consistent conditions to allow for accurate performance comparisons between methodologies.
For instance, if a model developed using Methodology A with extensive data outperforms a model using Methodology B with less data, we can't conclusively say that Methodology A is superior without considering the data volume differences. Effective experiment management helps us control such variables and make more valid comparisons.
Moreover, team collaboration and client interactions often lead to changes in training data, complicating the comparison of models from different experiments. For example, if a client requests a last-minute change to the training data, it's essential to have detailed records of the previous data and its processing. Without this, comparing past and current experiments' performance becomes challenging.
The potential for confusion exists not only between different team members but also within your own experiments. As you work on a project and collaborate with clients, changes to the training data are inevitable, making it challenging to accurately compare the model performance of different experiments. For instance, if you conducted an experiment a month ago and the client requests a last-minute change to the training data, it's crucial to have detailed records of the previous data and its processing. Without these records, or if reproducing the old data is too difficult, comparing the performance of new experiments with old ones becomes nearly impossible.
An experiment management system is indispensable for ensuring the success of AI projects. Here are key reasons why it’s necessary:
To address these needs, we established a set of principles for experiment management throughout the project and devised a systematic approach to manage them efficiently. Here’s how we created our experiment management system.
To efficiently manage experiments in AI model development projects, we have organized our experiment management into three main areas:
With this structured approach to data versioning, it’s straightforward to compare the performance of two experiments if the data versions used are, for example, v0.X.Y and v0.X.Z. Since the test sets are identical, any differences in performance can be attributed to changes in the model or methodology rather than variations in the data.
Managing Source Code Versions in Model Development
In a model development project, maintaining a record of the different attempts to improve model performance is crucial. With continuous trial and error, the direction of the project often changes. Consequently, the source code is in a constant state of flux. Without proper source code management, reproducing experiments can become challenging, and team members might find themselves rewriting code when they attempt to replicate methodologies.
To address these challenges, we focused on maintaining a one-to-one correspondence between experiments and source code versions. We managed our source code using Git Tags, and here’s how we did it:
💡 Experiment Process for Source Code Version Control
1.Pull Request Merge
When a team member wants to try a new experiment, they write a pull request (PR) with the necessary code. The rest of the team reviews the PR, and upon approval, it is merged into the main branch.
2.Git Tag Release
After merging the branch, a new release is created. We create a Git tag for this release, including a brief description in the release note. This description outlines the experiments that have been updated or the new features added to enhance the experiment’s visibility compared to the previous version.
3. Logging Git Tags When Running Experiments
When running an experiment, it’s important to log the Git tag in MLflow. This practice makes it easy to track which source code version each experiment was run on. In our project, we log the source code version of each experiment as an MLflow tag named src_version in the MLflow run.
By following this process, each source code version is systematically generated and released as a Git tag.

Source code version v0.5.1 release note
On the MLflow screen, the source code version is logged as an MLflow Tag. This allows users to check the “Columns” section to quickly see which source code version each experiment was run on.

TAME-Data-v0.4.0 part of Experiment display
When using MLflow to manage experiments, the Git Commit ID is automatically logged with each experiment. However, there are distinct advantages to using Git Tags to specify and log source code versions.
💡 Benefits of Using Git Tags for Source Code Versioning in AI Projects
1. Easily Identify Source Code Verisons
When viewing multiple experiments in the Experiments list, Git Tags allow you to see at a glance which experiments were run with the same source code version.
2. Understand the Temporal Order of Experiments
With Git Commit IDs, determining the order of experiments can be challenging since the commit hashes are random strings. Although you can compare commits directly, it’s not straightforward. Git Tags, on the other hand, provide version numbers that make it easy to understand the sequence of experiments. This is particularly advantageous for projects in the model development phase, where the temporal order of experiments is crucial.
3. Document Source Code Versions with Release Notes
Using Git Tags comes with the natural benefit of release notes, which document each source code version. As experiments accumulate, having detailed release notes helps in tracking methodologies and understanding the progression of the project. This documentation is invaluable for both code management and project traceability, offering insights into the project timeline and the context of each version.
As mentioned earlier, we use an open-source tool called MLflow to manage our experiments effectively, especially in an AI project with dozens to tens of thousands of experiments. Here’s an explanation of how MLflow is utilized to manage these experiments.
The key to recording experiments in MLflow is ensuring comprehensive and clear descriptions. Below is a detailed example.
First, MLflow Experiments were created for each data version to facilitate performance comparisons. In the Description section of each MLflow Experiment for a data version, a brief description of the data version is provided.
Below is one of the example screens for MLflow Experiment.

Example MLflow screen for Data Version v0.4.0
In the Description section of the MLflow screen for Data Version v0.4.0, the following details are included:
Will this help us manage experiments perfectly if we write detailed descriptions? As the model evolves and multiple data versions emerge, finding the right experiment can become time-consuming. To address this, experiments are recorded in separate spaces based on their purpose, making it easier to locate specific experiments later.
To organize experiments according to their purpose, the following spaces were created:

Separated experimental spaces based on the purpose of the experiment
[Type 1] Project Progress Leaderboard
This space records experiments to show the overall progress of the project. As the data version changes, experiments that perform well or are significant for each version are recorded here, providing a comprehensive overview of the project’s development.
[Type 2] Data Version Experiment Space
This is the main experiment space where all experiments are recorded according to the data version. With a focus on comparing model performance across experiments, an experiment space is created for each data version. Detailed information about the data used to train the model, model parameter values, and other relevant details are recorded to ensure the reproducibility of experiments.
[Type 3] Experiment Space for Test Logging
The test logging space serves as a notepad-like environment. It is used to verify whether experiment recording works as intended and is reproducible during source code development. This space allows for temporary, recognizable names (like the branch name being worked on). Once test logging confirms that an experiment is effective, the details are logged back into the main experiment space, the “[Type 2] Data Version Experiment Space.”
[Type 4] Hyperparameter Tuning Experiment Space
All hyperparameter tuning experiments for the main experiments are logged in this separate space. This segregation ensures that the main experiment space remains focused on comparing the performance of different methodologies or models. If hyperparameter tuning experiments were logged in the main space, it would complicate performance comparisons. Once a good hyperparameter combination is found, it is applied and logged in the main experiment space. Logging hyperparameter exploration helps in analyzing trends, which can narrow down the search space and increase the likelihood of finding better-performing hyperparameters. For example, here's a graph that analyzes the trend of depth, one of the hyperparameters in the CatBoost model.

Trend analysis graph of the depth hyperparameter in CatBoost models
When we set the search space of depth to 2–12, the resulting trend analysis graph revealed a positive correlation between the depth and the validation set performance, as indicated by the Pearson correlation coefficient (r). This analysis suggests that higher values of depth tend to yield better performance. Therefore, a refined strategy would be to narrow the search space to values between 8 and 11 for further tuning.
Separating the experimental spaces based on the purpose of the experiment not only makes it easier to track and find specific experiments but also, in the case of hyperparameter tuning, helps in uncovering valuable insights that can significantly improve model performance.
Assessment on Organizing Experiment Management
In our AI project, organizing experiment management became a crucial task. Here's what we learned about structuring our experiment management and how it has helped us advance the project.
What Worked Well: Seamless Collaboration and Efficient Comparison of Experiment Methodologies
With an organized experiment management system, collaboration across the team became more seamless. For instance, a teammate might say, “I tried an experiment with Method A, and here are the results,” then share a link to the MLflow experiment. Clicking the link reveals a detailed description of Method A, the data version used, and the source code version. This setup allows me to read the description, modify the code in that specific source code version, and run a similar experiment with slight variations. Without this system, re-implementing Method A would be inefficient, potentially leading to inconsistencies and difficulties in comparing the performance of newly developed models.
Beyond facilitating collaboration, this approach also helps us identify directions to improve model performance. By comparing the average performance between methodologies, we can focus on comparable experiments rather than sifting through a disorganized collection of experiments.
What To Improve: Inefficiencies and Human Error
While our experiment management system improved organization, we also focused on maintaining source code versions for all experiments. The model development cycle typically followed this pattern: conceive a methodology → implement the methodology in code → submit a pull request → review the pull request → run the experiment. However, this cycle sometimes introduced inefficiencies, especially when quickly trying and discarding various methodologies. To address this, setting clear criteria for quick trials and establishing exception cases can help avoid unnecessary processes and streamline experimentation.
Additionally, we created a src_version key in the config file to log the source code version in MLflow and recorded it as an MLflow Tag. However, manual modifications to the config file during experiments led to human errors. Automating this process as much as possible is essential to minimize errors and enhance efficiency.
In this blog, we’ve discussed the importance of experiment management and how creating an effective experiment management system helped us successfully complete our project. While the core principles of AI projects remain consistent, each project may have slightly different objectives, so it’s beneficial to customize your experiment management system to suit your specific needs. In the next post, we’ll share more about how MakinaRocks’ experiment management expertise is applied to our AI platform, Runway, to eliminate repetitive tasks and increase the efficiency of experiments.
We stand on the brink of a new era, fueled by the rapid advancement and integration of Artificial Intelligence (AI). Today, the manufacturing industry is poised to undergo a transformation unlike any it has seen before.
While the transition from manual labor to automated processes marked a significant leap, and the digital revolution of enterprise resource management systems brought about considerable efficiencies, the advent of AI promises to redefine the landscape of manufacturing with even greater impact.
Central to this transformation are Large Language Models (LLMs) and generative AI technologies. These tools are significantly lowering the barrier to entry for subject matter experts and field engineers who traditionally have not been involved in coding or "speaking AI." The impact of this should not be underestimated. Up to 40% of working hours across industries could be influenced by the adoption of LLMs, a significant shift in workforce dynamics.
AI, and particularly LLMs, will have a profound impact on the manufacturing sector. The opportunities are vast — but there are potential challenges, too.
AI is reshaping the very fabric of manufacturing, transforming traditional automation frameworks that adhere to ISA-95 standards at every level. This new era of automation heralds increased productivity and the emergence of innovative manufacturing practices, all driven by AI.
The integration of hardware automation, spearheaded by advances in robotics, combined with software automation led by AI, is crucial to unleashing the full potential of these innovations.
Yet, despite these advancements, AI remains an alien concept to many within the manufacturing industry. Subject matter experts, the seasoned engineers who intuitively understand machinery and production processes, find themselves at a crossroads. As these experts retire, their invaluable knowledge and insights risk being lost, underscoring the need for AI's integration into manufacturing to bridge this gap.
LLMs are set to revolutionize the manufacturing industry by serving as a conversational gateway between humans and machines, enabling assets and machinery to "communicate" with humans.
By interpreting vast amounts of manufacturing data, LLMs facilitate informed decision-making and pave the way for the future use of natural language in production and management.
This symbiotic relationship between AI and humans enhances the intelligence and efficiency of both parties, promising a future where AI's impact on manufacturing is more transformative than the industrial revolutions of the past.
In this future, AI amplifies human expertise, creating a collaborative environment where decision-making is faster, more accurate and informed by insights drawn from data that was previously inaccessible or incomprehensible.

An industrial LLM encapsulating all layers of the manufacturing plant, from machinery to AI-driven analytical solutions, will be able to manage and optimize entire operations.Image: MakinaRocks
The integration of AI into manufacturing extends beyond simple automation, encompassing areas like control optimization. By analyzing vast datasets, AI enhances production efficiency and reduces costs through the optimization of manufacturing processes. This not only smooths operations but also minimizes resource waste.
Reflecting the importance of these technological advancements, research shows that 75% of advanced manufacturing companies prioritize adopting AI in their engineering and R&D strategies. This commitment underscores AI’s key role in the future of manufacturing, guiding the sector toward more efficient and sustainable practices.
In the not-too-distant future, AI will be able to manage and optimize the entire plant or shopfloor. By analyzing and interpreting insights at all digital levels—from raw data, data from enterprise and control systems, and results of AI models utilizing such data—an LLM agent will be able to govern and control the entire manufacturing process.
For AI and LLMs to truly transform manufacturing, they must first be tailored to specific domains. This customization requires not only connecting to the right data sources but also developing tools for effective prompting that align with the unique challenges and processes of each manufacturing sector.
Domain specificity ensures that AI solutions are relevant, practical and capable of addressing the nuanced demands of different manufacturing environments. This demonstrates the need for industrial LLMs (or domain-specific LLMs) for proper and accurate application of LLMs in manufacturing.
In addition to domain-specific tailoring, the widespread and successful adoption of AI in manufacturing necessitates standardized development and operational processes. Establishing common frameworks and protocols for the implementation of AI technologies is critical to ensure compatibility, interoperability and security across different systems and platforms.
Standardization also facilitates easier adoption and integration of AI technologies, helping manufacturers to navigate the transition to AI-powered operations with greater ease and efficiency.
The AI transformation in manufacturing is set to usher in an unprecedented level of innovation. To keep pace with this rapid advancement, manufacturing leaders must make timely and informed decisions.
Preparing for this shift means implementing organization-wide AI transformation initiatives to standardize the AI development and operations processes and laying the foundation to fully leverage the benefits AI offers.
As the manufacturing industry stands at the cusp of this new era, the integration of AI promises to bridge the gap left by retiring experts and propel the sector towards a future of unparalleled efficiency and innovation.
The journey towards AI-enabled manufacturing is complex and fraught with challenges, but the potential rewards make it an endeavor worth pursuing.
Explore further insights on the significance of large language models by visiting the World Economic Forum (WEF) website.
From AlphaGo to Atari, Reinforcement Learning (RL) has shown exceptional progress in the gaming arena. Designing an RL environment for such tasks is relatively simple, as the training can be performed in the target environment without many constraints. When working with real-world tasks, designing the training environment is one of the main challenges. When applying RL to industrial tasks, there are mainly three ways of designing the training environment:
This blog post will share the process of building our custom RL training environment and some ways it can be used.

Off-line programming (OLP) is a robot programming method that lowers the production stoppage time when compared to online teaching. This is done by generating the robot’s path using a high-fidelity graphical simulation (digital twin) and later calibrating the output path to the real robot. The current OLP methods still rely on manual labor and can take several months to be completed, thereby discouraging changes to the production line, which may incur large costs. Our goal is to reduce the time needed to produce optimal robot paths by applying Reinforcement Learning. For more information about MakinaRocks’s current RL applications, please check our blog post (KR).
For the training environment, we defined the following requirements:
Based on those requirements, we developed the following modules:
Building the environment was an iterative process. As we learned more about the real process and fine-tuned our requirements, we also changed the training environment to better match said requirements.
The first version of our environment was built on Unity 2018.4 and used a simple 4 degrees of freedom (DOF) robot, which was controlled by applying torques directly to its joints. However, our application is more concerned about the joint positions than the torque applied to them. Also, most of the industrial robots have at least 6 DOF.

Therefore, we updated our environment to use a simple 6 DOF robot, which was controlled by directly setting the desired end-effector pose. This control value was then transformed into the joint space using an Inverse Kinematics module. Nonetheless, both the robot kinematic chain and motion were not realistic enough.

This led us to update the Unity version used in our project to version 2020.1. This Unity release has an updated physics engine with some new additions focused on robotics, namely PhysX articulation joints. This new joint type allowed us to realistically simulate kinematic chains and their motion. In addition, we updated our environment with a simulated version of the Universal Robots’ UR3e, which was controlled by setting the desired joint positions and velocities directly. Finally, we added a direct connection to ROS.

Even though the environment V3 used a real robot, it still could not match the complexities of robots found in large industries. Hence, we decided to change the robot model to a Kuka KR150, which is used in several industrial applications such as welding and painting. Moreover, we added a spot welding end-effector. These changes were important for us to visualize how the robot kinematic chain and size impacts the agent’s performance.

The flexibility of our training environment allows us to efficiently apply a large variety of algorithms. In this blog post, we will describe one of them.
Imitation learning (IL) is a field that tries to learn how to perform a task based on “expert” demonstrations. Generative Adversarial Imitation Learning (GAIL)[1] is one of the most famous IL algorithms. In a similar way to Generative Adversarial Networks[2], it trains a “Discriminator” that learns to differentiate between expert trajectories and the agent trajectories. At the same time, the agent is trained to maximize the discriminator error, i.e. it learns how to fool the discriminator by “imitating” the expert. Despite being able to learn from a small number of expert trajectories, increasing the number of demonstrations, or performing data augmentation has been shown to improve GAIL’s performance[3]. When working with real robots, however, obtaining enough expert trajectories can pose a number of issues.
If moving the robot manually, the quality and the consistency of the expert trajectories can be degraded. Due to the need for a large amount of data, the operator fatigue or lack of concentration can lead to sub-optimal trajectories. Controlling a robot in the joint space can be counter-intuitive and hard to manually control, leading to the usage of external proxies such as virtual reality controllers[4], exoskeletons[5], or full-body tracking[6] as a way to simplify the process for the operator. Nonetheless, such devices add extra costs and require time for developing and setting up the whole system. Finally, when the expert trajectories and the agent trajectories come from different domains, the discriminator can easily overfit to small differences between both domains, making it impossible for the agent to learn[7].
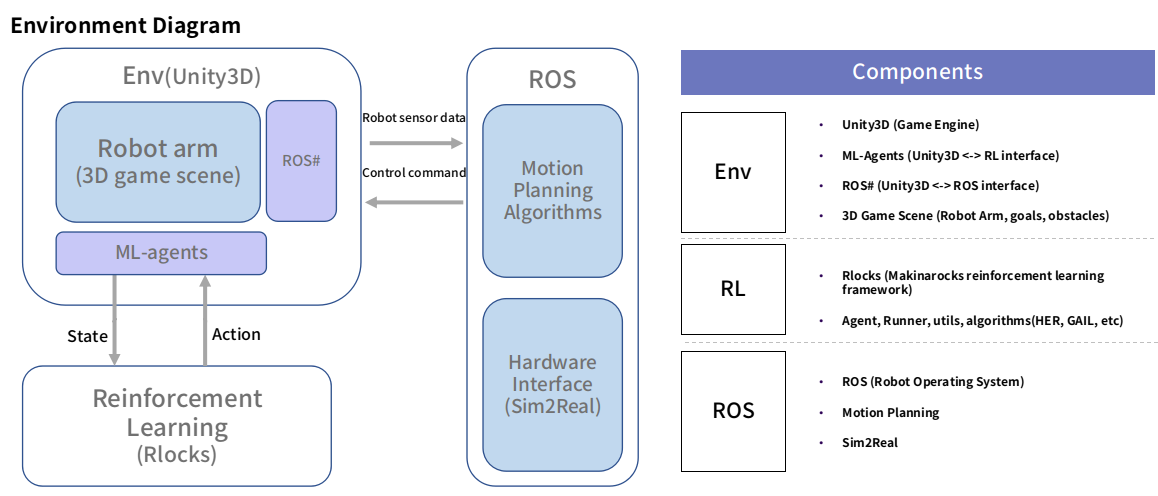
Our framework can overcome said issues by automating the expert trajectory generation using state-of-the-art classical approaches included in ROS. MoveIt is an open-source ROS package that can perform motion planning, manipulation, collision avoidance, control, inverse kinematics, and 3D perception. We developed a ROS hardware interface to work as a middleware between MoveIt and Unity3D to isolate both modules from each other. In other words, the MoveIt side sent the same commands it would send to a real robot, while the Unity side received the same commands it would receive from the RL agent. We were then able to run MoveIt in a loop, while sampling the commands on the Unity side, enabling both expert and agent trajectories to be sampled from the same domain. As the whole process is automated, one can generate as many expert trajectories as needed.
We sampled expert trajectories for 6 hours (approximately 1000 trajectories) and ran the GAIL training for 24 additional hours. The result of this training can be seen in the video below:
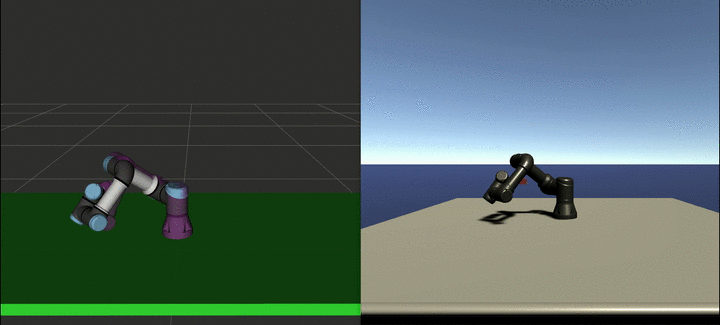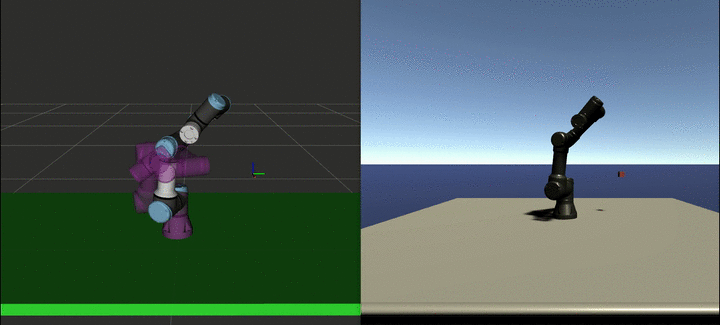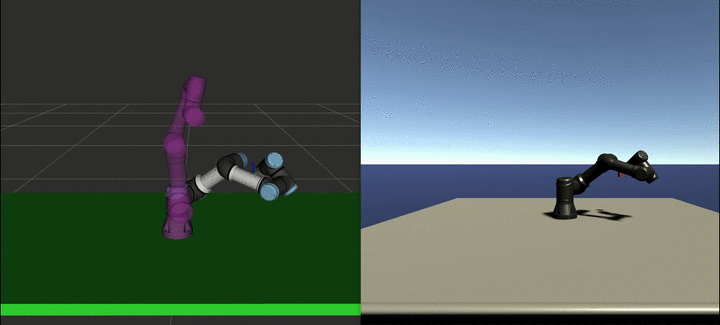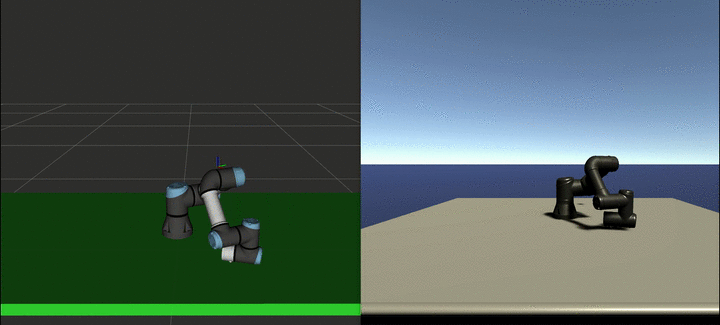

Depending on the task complexity, planning with MoveIt can take from a few seconds to several minutes. On the other hand, the agent can generate the path in real-time. Moreover, this policy can be further improved using curriculum learning, so that it can perform more complex tasks.
This blog post shared how we developed our custom reinforcement learning environment and one of our applications. We plan to add more functionalities and applications as our research progresses. We look forward to sharing more of MakinaRocks’s technical developments in the near future.







