


앞서 설명한 포스팅에서 파이프라인은 MLOps 도입을 위한 필요한 요소라고 설명했습니다. 이번 포스팅에서는 파이프라인이란 무엇이고, 왜 필요하며, 어떤 오픈 소스들이 있는지를 소개합니다.
Pipeline
 pipeline
pipeline
정의
그럼 대체 파이프라인은 무엇일까요? 사실, 파이프라인이 갑자기 MLOps에서 나온 용어는 아닙니다. 파이프라인 자체는 데이터를 다루는 곳에서 많이 사용하던 용어입니다. 이에 대한 정의는 다음과 같습니다.
컴퓨터 과학에서 파이프라인(영어: pipeline)은 한 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 형태로 연결된 구조를 가리킨다. 이렇게 연결된 데이터 처리 단계는 한 여러 단계가 서로 동시에, 또는 병렬적으로 수행될 수 있어 효율성의 향상을 꾀할 수 있다. 각 단계 사이의 입출력을 중계하기 위해 버퍼가 사용될 수 있다.
출처: 위키피디아
구성 요소
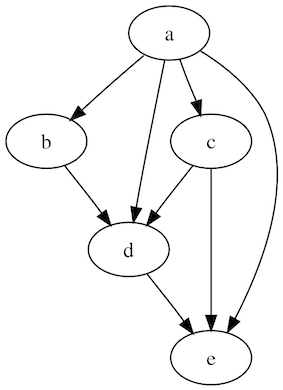
DAG
파이프라인을 만들기 위해서는 컴포넌트(Component) 와 DAG(Directed acyclic graph)가 필요합니다. 컴포넌트란 앞서 정의에서 설명한 것에서 하나의 처리를 의미합니다. 그리고 각 처리의 결과물이 다음으로 이동하기 위한 단계가 있으며, 이 두 가지를 합친 것을 DAG라고 부릅니다.
위 그림은 DAG를 표현한 예시 그림입니다. 그림에서 a, b, c, d, e 는 컴포넌트를 뜻합니다. a → b 로 이동하는 화살표는 a의 결과물이 b로 이동해야 한다는 단계를 의미합니다.
Machine Learning Pipeline
정의
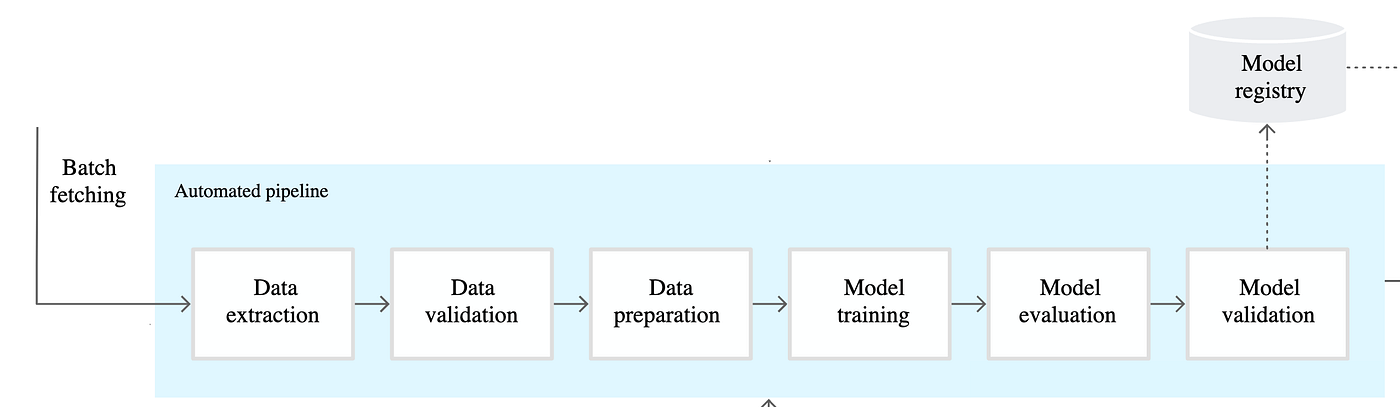 Machine Learning Pipeline
Machine Learning Pipeline
그럼 머신러닝 파이프라인은 앞서 설명한 파이프라인과 무엇이 다를까요?
머신러닝 파이프라인의 목적은 입력 받은 데이터를 이용해 학습한 모델을 출력하는 것에 있습니다.
위의 그림은 앞선 포스트에서 사용한 구글 클라우드에서 제시한 MLOps 1단계에서 파이프라인입니다.
파이프라인 내부에서 사용하는 과정에 대해서는 사용하는 환경마다 다를 수 있습니다. 하지만 모델을 학습하기 위해서 필요한 데이터를 입력받는 부분(Batch fetching)과 학습된 모델을 저장하기 위한 모델 저장소(Model Registry)는 ML 파이프라인에서는 필수적인 요소입니다.
그렇기 때문에 파이프라인을 개발할 때는 데이터를 전달 받을 수 있는 구조를 고려하고 학습된 모델을 지정된 모델 저장소로 전달할 수 있어야 합니다.
특성
ML 파이프라인은 재현성(Reproducibility)과 재 사용성(Reusability) 두 가지 특성을 만족해야 합니다.
1. Reproducibility
왜 재현성이 필요한지는 최근 Meta 의 테크 리드가 올린 포스팅을 통해 그 필요성을 엿볼 수 있습니다.
머신러닝 실험에서 가장 중요한 것은 재현성(reproduciblity)인데 많은 머신러닝 엔지니어들이 이러한 부분을 간과하고 있습니다. 예를 들어 개인 랩탑에서 사용한 코드를 복사해 GPU가 있는 서버에 붙여 넣은 후 사용하는 경우입니다. 이러한 행동과 재현성은 어떤 관련이 있을까요?
이론적으로 모델을 학습하는데 영향을 미치는 요인으로는 데이터와 아키텍쳐가 있습니다. 하지만 실제로 모델을 학습하면 동일한 데이터와 아키텍쳐를 사용한다고 해도 동일한 결과를 낼 수 없습니다.
이는 데이터와 아키텍쳐 외에도 영향을 미치는 요인들이 있기 때문입니다. 그 중 많은 머신러닝 엔지니어들이 간과하는 부분이 바로 OS, 파이썬과 패키지 버전입니다.
OS는 난수를 생성하는 과정에 크게 영향을 미칩니다. 난수가 필요한 경우는 초기 가중치를 무작위로 설정하는 부분, 학습에 사용할 배치를 무작위로 뽑는 방법에 사용됩니다.
파이썬과 패키지 버전은 가중치를 업데이트 하는 방법 등에 영향을 미칩니다.
이러한 이유로 성능이 잘 나오던 모델이 다른 곳에서 학습을 할 때는 원래 성능이 재현되지 않는 문제를 자주 볼 수 있습니다.
원래 성능이 재현되지 않는 문제를 해결하기 위한 필요 조건으로는 ‘어느 곳에서 실행되어도 같은 성능을 낼 수 있는 모델이 학습될 수 있음’을 보장해야 합니다. 그리고 많은 MLOps 플랫폼들은 컨테이너를 이용해 이 문제를 해결하고 있습니다.
컨테이너는 소프트웨어 서비스를 실행하는 데 필요한 특정 버전의 프로그래밍 언어 런타임 및 라이브러리와 같은 종속 항목과 애플리케이션 코드를 함께 포함하는 경량 패키지입니다.
출처: 구글 클라우드
도커(Docker)는 이러한 컨테이너 플랫폼의 가장 대표적인 소프트웨어이기 때문에 MLOps와 관련된 글에서 종종 도커와 관련된 내용을 확인할 수 있습니다.
플랫폼으로 이용하기 위해서는 컨테이너 기술만이 아니라 여러 컨테이너를 조율(Ochestration) 할 수 있어야 합니다. 이를 위한 소프트웨어가 바로 쿠버네티스(Kubernetes)입니다. 쿠버네티스는 컨테이너 관리와 더불어 자원 관리, 네트워킹, 보안 등 여러 필요한 기능을 지원하는 소프트웨어로서 Container Ochestration 에서 사실상 표준(De facto standard)이라고 볼 수 있습니다.
2. Reusability
잘 설계된 파이프라인은 한 번만 사용 되는 것이 아니라 계속해서 재 사용할 수 있습니다. 어떻게 재 사용할 수 있을까요?
앞서 파이프라인의 입력으로 학습에 필요한 데이터를 받아야 된다고 설명했습니다. 이 부분을 잘 설계한다면 입력 받는 데이터를 머신러닝 엔지니어가 처음에 의도한 것 뿐만 아니라 다른 데이터를 이용해서도 모델을 학습할 수 있습니다.
이러게 새로운 데이터로 새로운 모델을 학습할 수 있다면 MLOps 1단계에서의 Continuous Traning이 가능해 집니다.
또한 입력으로 데이터에 더해 모델을 학습하는데 필요한 하이퍼 파라미터를 같이 받는다면 여러 파라미터 값을 이용해 최적의 파라미터 값을 탐색할 수 도 있습니다.
Open Source of Pipeline
Usage
글을 작성하는 기준으로 파이프라인을 생성하는 오픈 소스들로는 Airflow, Kubeflow 등이 있습니다. 이외에도 다양한 MLOps 플랫폼에서 이를 지원하기 위한 독자적인 방법들을 사용하고 있습니다.
사용법은 크게 2가지가 있습니다.
- 특정 단위(function)로 컴포넌트를 만든 후 각 컴포넌트의 관계를 이어준다.
- 사전에 정의된 함수 또는 클래스에 모델을 생성하는데 필요한 코드들을 작성한다.
1번 방법의 장점은 만들어진 컴포넌트를 다른 파이프라인에서 재 사용할 수 있다는 것입니다. 또한 컴포넌트 별로 캐싱 기능을 사용해 파이프라인 수행 시간을 줄일 수 있습니다. 반면, 단점으로는 생성된 컴포넌트들을 연결하기 어렵다는 점이 있습니다.
2번 방법의 장점은 추가 작업 없이 기존에 사용하던 스크립트를 바로 재 사용할 수 있습니다. 단점으로는 컴포넌트의 재 사용이 어렵고 매번 코드의 처음부터 끝까지 실행이 됩니다.
하지만 1번과 2번 방법 모두 가장 큰 어려움은 는 바로 데이터 과학자와 머신러닝 엔지니어들이 파이프라인을 작성하기 어렵다는 것입니다.
예를 들어, Kubeflow의 경우 파이썬의 데코레이터(Decorator)를 이용해 컴포넌트와 파이프라인을 작성해야 합니다. 또한, 로컬 개발 환경에서는 실행해 볼 수 없어 파이프라인을 클러스터에 업로드해 실행을 하면서 동작하는 파이프라인을 작성해야 합니다.
Link™
마키나락스에서는 이러한 문제를 해결하기 위해서 Link™를 개발했습니다. Link™는 데이터 분석과 모델링을 할 때 가장 많이 쓰이는 Jupyter 환경에서 바로 파이프라인을 만들 수 있도록 지원하는 기능을 지원합니다. 또한 작성된 파이프라인을 Kubeflow 에서 사용 가능한 yaml로 변환할 수 있습니다.
Link™️의 커뮤니티 버전은 링크를 통해 설치할 수 있으며 자세한 내용은 공식 문서를 참고하길 바랍니다.
» 이 글은 마키나락스 미디엄에 게재된 포스팅으로 원문은 여기서 확인하실 수 있습니다.
















